What follows is a Persian translation of Gregory Crane’s “Visualizing Progress in Homeric Greek”, available in English online at: https://sites.tufts.edu/perseusupdates/2022/04/19/visualizing-progress-in-homeric-greek-1/. The translation is made available here courtesy of Aylar Mahmoudzadeh Sarabi.
مصورسازی پیشرفت در حماسۀ هومری
گرگوری کرین
برگردان فارسی: آیلار محمودزاده سرابی
طرح مقالۀ حاضر اولین مورد از دو مقالهایی است که بررسی میکند فراگیران قادرند تا چه میزان، چه تعداد از کل واژگان را در پیکرۀ هدفی که پیشتر با آن مواجه شدهاند بازشناساند و نیز نمایانگرِ بسامد واژگان جدیدی است که در ادامۀ پیکره با آن مواجهاند. بدین منظور ما بر روی متون ایلیاد و ادیسه به زبان یونانی باستان متمرکز شدیم، پیکرهایی زبانی که مجموع واژگان به کار رفته در آن کمی بیش از ۲۰۰۰۰۰ واژه است. حماسۀ هومری پیکرهایی است که به دلیل دارا بودن مجموعهایی رو به رشد از منابع دیجیتال با دسترسی آزاد، شروعِ سودمندی را برای ما فراهم مینماید؛ هر صورت از واژگانِ این پیکرۀ حماسی توسط لینکهایی به مداخل مربوط در فرهنگ لغت قابل ارجاع است که این خود نقطۀ شروع تحلیل واژگانی به حساب میآید.
مطالعۀ دیگر بخشی از یک پروژۀ گستردهتر به نام Beyond Translation است، پروژهایی که با بودجۀ حمایتی NEH در جریان است. در این مطالعه ما در حال توسعۀ روشهایی هستیم تا فراگیران بتوانند در کلِ متون دیگری که واژۀ یونانی جدیدی مشاهده میکنند به جای متکی بودن به لغت نامۀ کتاب آموزشی، خودشان معنی آن واژه را بفهمند؛ بدین ترتیب که فراگیران از همان روز نخست از طریق تطبیق ترجمه با متن اصلی در سطح واژه و عبارت، خواندن واژهها در بافت متن را شروع میکنند. این روند همچنین شامل شرح تحلیل زبانی برای نقش هر واژه است. با این حال این مقاله صرفاً بر این موضوع متمرکز است که فراگیران چطور میتوانند از عهدۀ سازماندهی کردن فراگیری واژگان بر اساس بسامد پیکره و سپس پیگیری پیشرفت خود برآیند.
در طراحی این مقاله از کتاب «یونانی هومری» اثر کلاید فار[۱] نیز استفاده شده است؛ سرآغازی برجسته و بدیع برای شروع نمودن زبان یونانی باستان که حدود یک قرن پیش نوشته شده است. فار در صفحۀ شمارۀ ۱ کتاب دستور خود، فراگیران را با تعدادی از واژگان به کار رفته در بندهای ۵-۱ کتاب اول ایلیاد آشنا میکند. او از درس ۱۳ به بعد شروع به گنجاندن قطعات کوچکی از کتاب اول ایلیاد در درسها مینماید که طول این قطعات بتدریج بزرگتر میگردد و تا آخر درس ۷۷ در نهایت ۶۱۱ خط از این کتاب را در برمیگیرد. بر این اساس، کتاب اول ایلیاد به عنوان پیکرۀ هدف مورد استفاده قرار میگیرد و فراگیران تا حد امکان با یادگیری کل ۴۵۶۳ واژۀ این کتاب به شناختی از زبان یونانی پایه میرسند.
پژوهشگرانی که زبانهای مدرن [۲] را بررسی مینمایند معمولاً بیان میکنند خوانندگان به منظور دستیابی به درک رضایت بخشی از یک متن، حداقل باید ۹۵ درصد و ترجیحاً ۹۸ درصد از کل واژگان متن را بفهمند. رسیدن به سطح آستانۀ [۳] ۹۵ درصد اغلب از سوی مدرسان متبحر زبانهای یونانی باستان و لاتین ذکر میگردد. حماسۀ هومری متن متفاوتی است و قابلیت بیشتری دارد تا بتوان قبل از دستیابی خوانندگان به دانش واژگان ۹۵ درصدی خوانده شود. زبان آموزان یونانی معمولاً عنوان میکنند قادرند خیلی زود و به صورت سریع و روان خواندن یونانی هومری را شروع کنند – که کاملاً با تجربۀ شخصی من مطابقت دارد، وقتی در دهۀ ۱۹۷۰ با تمام وجود هومر میخواندم، مدتها پیش از آنکه ابزار دیجیتال در دسترس باشند. چه بسا ماهیت الگومند شعر هومری بدین معنا است که رد شدن از واژگان حین خواندن آسانتر است – به طور قطع صفات متداول بسیاری وجود دارند که (به نظر من) ترجمههای سنتی صورت گرفته بدین منظور، حدسهاییاند که بر پایۀ بافت متن استوارند.
افزون بر این، وقتی ما کل ادبیات یونانی باستان را مورد پژوهش قرار میدهیم از ژانری به ژانر دیگر تغییر جهت میدهیم، از هومر به تراژدی آتیک [۴]، از مورخانی مثل هرودت [۵] (که به گویش ایونی [۶] مینویسند) تا توسیدید [۷] ( که به گویش آتیک [۸] مینویسد)، از کمدیهای آریستوفان [۹] تا دیالوگهای افلاطون [۱۰]. خالقان مختلف و ژانرها، دارای سبک و واژگان متفاوتاند. فراگیری مقدار بسندهایی از زبان یونانی باستان از منابع متعدد برای همه دشوار است اما از با تجربهترینها انتظار میرود که ۹۵ تا ۹۸ درصد از واژهها را در متنی که از پیش ندیدهاند بفهمند. بیشتر خوانندگان یونانی باستان به استفاده از فرهنگهای لغت آنلاین نیاز خواهند داشت. هدف من تا حد توان کمک به نهادینه کردن دانش فراگیران است و اینکه تا حد امکان با سهولت، دقت و رضایت با این منابع آشنا شوند.
گرچه فار تا آنجا که ممکن است خوانندگاناش را به هومر نزدیک میکند اما کار خود را به متن یونانی اصیل محدود نمیکند. فار تمریناتی را در کتاب خود گنجانده است که به منظور استفاده در کتاب آموزشی نوشته شدهاند و از فراگیران میخواهد تا این تمرینات را ترجمه کنند. اما تقریباً کل واژگان این کتاب آموزشی از کتاب اول ایلیاد استخراج و به گونهایی طراحی شدهاند تا فراگیران همچنان که یک سری از واژههای کتاب اول ایلیاد را در عمل به کار برده و میآموزند [۱۱]، بتوانند واژههایی را هم که عملاً به کار نبردهاند از روی فرم صوریشان باز شناساند [۱۲].
البته، چنین تمریناتی هر آنچه را که فراگیران در هر درس آموخته و یا نیاموختهاند به دقت دنبال میکند. با وجود این که جان رایت [۱۳] و پائولا دبنر[۱۴] شرح دستور کتاب فار را کاملاً بازنویسی کردهاند اما تمرینات فار را با دقت نگه داشتهاند (فار ۲۰۱۲). در نهایت ما باید بتوانیم چنین تمریناتی را به طور خودکار از پیکرۀ زبانی حاوی شرح وتعلیقات زبانی و متنی تولید کنیم – که با توجه به وضعیت پردازش زبان طبیعی، در حال حاضر نیز میتوانیم انجام دهیم – اما فعلاً آنها را بر اساس تمریناتی که یک قرن پیش توسط فار و به صورت دستی ایجاد شدهاند، میسازیم.
من فرض میکنم که فراگیران به جای تولید و درک مؤثر شماری نامتناهی از گفتار در یک زبان زنده، به منظور تسلط بر پیکرۀ موجود تلاش میکنند. البته این کاربرد میتواند موارد استفاده با زبان مدرن را توصیف نماید که در آن فراگیر میخواهد که یک پیکرۀ خاص را بفهمد. به عنوان مثال – فیلمنامۀ فیلمی از کوروساوا [۱۵] و یا ترانههای گریت فول دد [۱۶]- آنها میتوانند پیشرفت خود را با پیکرهایی بسنجند که حداقل در حال حاضر نسبتاً ثابت است.
با تکیه بر نمودارهای درختی متعددی که دسترسی به آنها آزاد است، حاشیه نویسیهایی به صورت دستی تنظیم شدهاند که فرهنگ لغت، مقولۀ دستوری و نیز نقش نحوی را برای مجموع بیش از ۱ میلیون واژۀ یونانی باستان فهرست کرده، در بستر GitHubقرار داده است. از این مقدار واژگان، حدود ۲۰۰۰۰۰ واژه مربوط به کل ایلیاد و ادیسه است. بنابراین میتوانیم با شروع اندازهگیری عواملی مانند تعداد واژههای فرهنگ لغت و حالتهای صرفی، شمار آنها را در حماسۀ هومری به دست آوریم.
واژگان در حماسههای هومری
شمارش دقیق، بر اساس نسخۀ انتخاب شده (نمودار درختی پرسئوس برای هومر از نسخۀ سال ۱۹۲۰ آلن متعلق به مجموعۀ متون کلاسیک آکسفورد[۱۷] استفاده میکند) و نیز نحوۀ شمارش کلمات (نموداردرختی پرسئوس کلماتی مانند mête «هیچکدام» را به عنوان دو کلمه در نظر میگیرد: mê «نه» و te «نیز، و») متفاوت خواهد بود. این تفاوت، تصمیمگیری در این مورد که آیا کلماتی خاص به یک، دو یا چند مدخل فرهنگ لغت اختصاص داده شوند را نیز شامل میشود. بعید است که این عوامل، تصویری را که در نمودار زیر ظاهر میشود تغییر دهند.
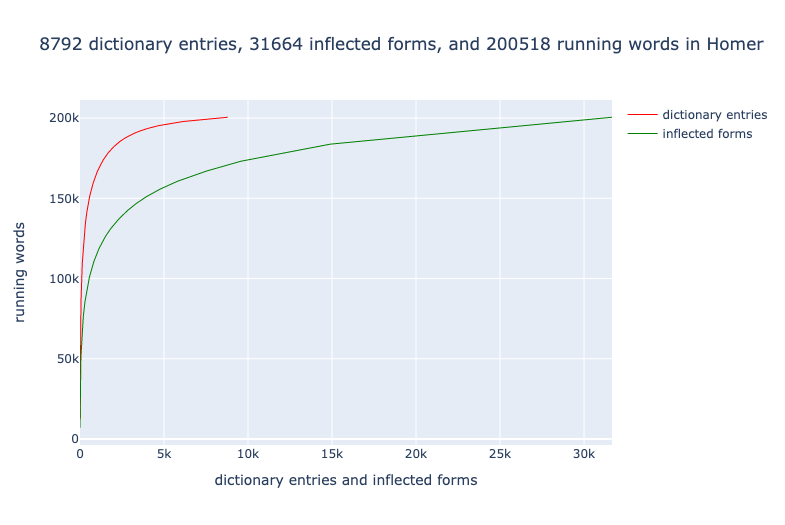
نمودار ۱ : عدد نسبی مداخل فرهنگ لغت و ساختهای صرفی در ایلیاد و ادیسه
نمودار ۱ سهم هر مدخل فرهنگ لغت و ساخت صرفی آن را در درک حماسۀ هومری به صورت کامل نشان میدهد. نمودار با متداولترین مداخل فرهنگ لغت و نیز ساختهای صرفی واژهها شروع میشود و همینطور که به پایین فهرست نزدیک میشود، بسامد هر مورد جدید را افزوده، شمار واژههایی را که در حال حاضر در حماسۀ هومری قادر به شمارش آن هستیم اندازهگیری میکند. نمودار ۱ به روشنی نشاندهندۀ این واقعیت است که یونانی زبانی است به شدت تصریفی، به طوری که هر مدخل فرهنگ لغت به طور متوسط۶ .۳ حالت مختلف دارد.
جدول زیر متداولترین صورتهای به کار رفته در حماسۀ هومری را نشان میدهد و اینکه هر کدام تا چه اندازه در مجموع ۲۰۰۵۱۸ واژۀ به کار رفته در کل پیکره سهیماند. بیشترِ صورتها، ادات و حروف اضافهایی هستند که صرفناشدنیاند. تنها شمار اندکی از این ۲۰ واژه، تصریفپذیر هستند. توجه داشته باشید که هیچ تلاشی مبنی بر بههنجارکردن [۱۸] صورتها انجام نگرفته است: بنابراین، به عنوان مثال، kai («و») با تکیهی افتان [۱۹]، به عنوان صورت متمایزی از kai در نظر گرفته میشود که با تکیه افتان نمود مییابد، گرچه این دو کلمه از لحاظ معنی یکسان هستند. بههنجارسازی [۲۰] ممکن است تعداد صورتها را کاهش دهد اما رابطۀ بین مداخل فرهنگ لغت و صورتهای موجود در نمودار ۱را به نحو قابل ملاحظهایی تغییر نخواهد داد.
| ۱ | δ’ | δέ | اما | ۷۱۰۴ | ۷۱۰۴ | ۰.۰۳ |
| ۲ | καὶ | καί | و | ۴۸۱۲ | ۱۱۸۲۶ | ۰.۰۵ |
| ۳ | δὲ | δέ | اما | ۳۴۶۱ | ۱۵۲۸۷ | ۰.۰۷ |
| ۴ | τε | τε | و | ۲۷۶۶ | ۱۸۰۵۳ | ۰.۰۹ |
| ۵ | δέ | δέ | اما | ۱۶۴۰ | ۱۹۶۹۳ | ۰.۰۹ |
| ۶ | μὲν | μέν | از طرفی | ۱۶۳۴ | ۲۱۳۲۷ | ۰.۱۰ |
| ۷ | οὐ | οὐ | نَه | ۱۵۶۰ | ۲۲۸۸۷ | ۰.۱۱ |
| ۸ | ἐν | ἐν | در | ۱۴۰۷ | ۲۴۲۹۴ | ۰.۱۲ |
| ۹ | τ’ | τε | و | ۱۲۲۲ | ۲۵۵۱۶ | ۰.۱۲ |
| ۱۰ | ὣς | ὡς | مثلِ | ۱۲۱۵ | ۲۶۷۳۱ | ۰.۱۳ |
| ۱۱ | γὰρ | γάρ | برای | ۹۶۷ | ۲۷۶۹۸ | ۰.۱۳ |
| ۱۲ | ἀλλ’ | ἀλλά | به گونهایی دیگر | ۹۳۳ | ۲۸۶۳۱ | ۰.۱۴ |
| ۱۳ | τὸν | ὁ | حرف تعریف معرفه ساز | ۹۰۴ | ۲۹۵۳۵ | ۰.۱۴ |
| ۱۴ | ἐπὶ | ἐπί | بر رویِ | ۸۲۹ | ۳۰۳۶۴ | ۰.۱۵ |
| ۱۵ | οἱ | ἕ | بدون معادل مشخص | ۸۰۴ | ۳۱۱۶۸ | ۰.۱۵ |
| ۱۶ | αὐτὰρ | ἀτάρ | اما | ۷۵۹ | ۳۱۹۲۷ | ۰.۱۵ |
| ۱۷ | μοι | ἐγώ | من (ضمیر اول شخص) | ۷۴۵ | ۳۲۶۷۲ | ۰.۱۶ |
| ۱۸ | δὴ | δή | ادات بر هم کنش | ۷۴۱ | ۳۳۴۱۳ | ۰.۱۶ |
| ۱۹ | οὔ | οὐ | نه | ۶۷۷ | ۳۴۰۹۰ | ۰.۱۷ |
| ۲۰ | μιν | μιν | ضمیر سوم شخص مفرد مذکر | ۶۴۴ | ۳۴۷۳۴ | ۰.۱۷ |
با در نظرگرفتن جدول فوق، درمییابیم که اغلب صورتهای پربسامد در پیکرۀ زبانی، صرفناشدنیاند و بنابراین نسبت ۶ .۳ به ازای هر مدخل فرهنگ لغت، شمار صورتهای مختلف بسیاری از واژهها را که مخاطبان در عمل با آنها مواجهاند به تمامی نشان نمیدهد. ( در تابستان ۲۰۱۹، وقتی اتان یتس [۲۱] صورتهای فهرست شده در پارادایمهای کتاب آموزش یونانی هومری اثر کلاید فار را تولید مینمود، فهرستی از حدودا ۱۴۰۰۰ صورت صرف شدنی مختلف به دست داد که پارادایمهای متفاوتی را نشان میدهد. اگر او میخواست تمام ادات صرفشدنی را درج نماید، فهرست به طرز چشمگیری طولانیتر میبود).
جدول زیر شمار ۲۰ مدخل متداول در حماسۀ هومری را نشان میدهد.
| ۱ | δέ | اما | ۱۲۱۳۸ | ۱۲۱۳۸ | ۰.۰۶ |
| ۲ | ὁ | حرف تعریف معرفهساز | ۵۸۷۰ | ۱۸۰۰۸ | ۰.۰۸ |
| ۳ | καί | و | ۵۲۸۳ | ۲۳۲۹۱ | ۰.۱۱ |
| ۴ | τε | و | ۴۳۲۲ | ۲۷۶۱۳ | ۰.۱۳ |
| ۵ | >ἐγώ | من(ضمیر اول شخص مفرد) | ۲۸۷۱ | ۳۰۴۸۴ | ۰.۱۵ |
| ۶ | οὐ | نه | ۲۶۹۵ | ۳۳۱۷۹ | ۰.۱۶ |
| ۷ | εἰμί | فعل (بودن) | ۲۱۱۸ | ۳۵۲۹۷ | ۰.۱۷ |
| ۸ | ἐν | در | ۲۰۷۶ | ۳۷۳۷۳ | ۰.۱۸ |
| ۹ | ὅς | چه کسی | ۲۰۴۳ | ۳۹۴۱۶ | ۰.۱۹ |
| ۱۰ | ὡς | مثلِ | ۲۰۰۷ | ۴۱۴۲۳ | ۰.۲۰ |
| ۱۱ | σύ | تو(ضمیر شخصی) | ۱۹۰۰ | ۴۳۳۲۳ | ۰.۲۱ |
| ۱۲ | μέν | از طرفی | ۱۸۷۲ | ۴۵۱۹۵ | ۰.۲۲ |
| ۱۳ | ἄρα | ادات: بنابراین | ۱۷۷۲ | ۴۶۹۶۷ | ۰.۲۳ |
| ۱۴ | τις | هر کس | ۱۴۵۷ | ۴۸۴۲۴ | ۰.۲۴ |
| ۱۵ | ἄν | ادات وجهی | ۱۴۴۹ | ۴۹۸۷۳ | ۰.۲۴ |
| ۱۶ | ἀλλά | به گونهایی دیگر | ۱۴۳۰ | ۵۱۳۰۳ | ۰.۲۵ |
| ۱۷ | γάρ | برای | ۱۴۰۱ | ۵۲۷۰۴ | ۰.۲۶ |
| ۱۸ | ἐπί | بر رویِ | ۱۳۷۱ | ۵۴۰۷۵ | ۰.۲۶ |
| ۱۹ | αὐτός | ضمیر شخصی غیر تاًکیدی،خود؛ یکسان | ۱۱۲۱ | ۵۵۱۹۶ | ۰.۲۷ |
| ۲۰ | πᾶς | همه | ۱۰۸۹ | ۵۶۲۸۵ | ۰.۲۸ |
نمودار فوق تعداد ۸۷۹۲ واژۀ مختلف فرهنگ لغت را از کل ۲۰۰۵۱۸ واژهایی که برای حماسهی هومری در نمودار درختی پرسئوس شمارش شده است را شرح میدهد. این نمودار نمونۀ خوبی برای افرادی است که با توزیع توانی آشنایی ندارند. ۲۰ واژهی پربسامد فرهنگ لغت – کمتر از ۱ از میان ۴۵۰ یا ۲۳%. ۰ – در مجموع ۵۶۲۸۵ واژه را به خود اختصاص داده است؛ یعنی بیش از یک چهارم از کل پیکره (%۲۸).
هزار مدخل پربسامد فرهنگ لغت (%۱۱ از کل) تعداد ۱۶۵.۹۲۲ واژه (%۸۲ از کل) را به خود اختصاص داده است. جدول زیر هر ۵۰ اُمین مدخل فرهنگ لغت را به منظور ژرفنمایی و نشان دادن میزان پیشرفت فراگیران – در صورت توجه به بسامد واژگان – فهرست کرده است. البته آنها احتمالاً راهبرد تعدیل یافتهایی را به کار میگیرند، به این نحو که به جای شروع با صورتهای متداول، ابتدا از اسامی متداول و سپس افعال، و جز اینها شروع کرده، به همین ترتیب پیش میروند.
| ۱ | δέ | اما | ۱۲۱۳۸ | ۱۲۱۳۸ | ۰.۰۶ |
| ۵۰ | μή | نه | ۶۱۴ | ۸۰۱۲۳ | ۰.۳۹ |
| ۱۰۰ | σφεῖς | ضمیر شخصی انعکاسی مضارع | ۲۹۴ | ۱۰۰۵۳۸ | ۰.۵۰ |
| ۱۵۰ | προσεῖπον | مخاطب قرار دادن | ۱۹۰ | ۱۱۲۰۶۱ | ۰.۵۵ |
| ۲۰۰ | ἄνωγα | دستور دادن | ۱۴۵ | ۱۲۰۳۴۴ | ۰.۶۰ |
| ۲۵۰ | πάσχω | تجربه کردن | ۱۱۸ | ۱۲۶۸۰۰ | ۰.۶۳ |
| ۳۰۰ | ἡμέτερος | ما | ۹۹ | ۱۳۲۲۴۸ | ۰.۶۵ |
| ۳۵۰ | θέω | دویدن | ۸۳ | ۱۳۶۸۱۴ | ۰.۶۸ |
| ۴۰۰ | ὅστις | ضمیر موصولی نامعین یا ضمیر پرسشی غیرمستقیم | ۷۳ | ۱۴۰۷۲۲ | ۰.۷۰ |
| ۴۵۰ | ἕλκω | کشیدن | ۶۵ | ۱۴۴۱۶۴ | ۰.۷۱ |
| ۵۰۰ | πάλιν | عقب | ۵۷ | ۱۴۷۲۰۸ | ۰.۷۳ |
| ۵۵۰ | τέμνω | بریدن | ۵۱ | ۱۴۹۹۱۱ | ۰.۷۴ |
| ۶۰۰ | ἔνθεν | از آنجایی که، از آنجا | ۴۵ | ۱۵۲۲۸۹ | ۰.۷۵ |
| ۶۵۰ | ἀλέομαι | اجتناب کردن | ۴۲ | ۱۵۴۴۴۶ | ۰.۷۷ |
| ۷۰۰ | φόβος | ترس | ۳۹ | ۱۵۶۴۵۸ | ۰.۷۸ |
| ۷۵۰ | ὀρέγω | رسیدن | ۳۶ | ۱۵۸۳۱۷ | ۰.۷۸ |
| ۸۰۰ | ἄρειος | بدون معادل مشخص | ۳۴ | ۱۶۰۰۶۱ | ۰.۷۹ |
| ۸۵۰ | δατέομαι | بین خود/ خودشان تقسیم کردن | ۳۱ | ۱۶۱۶۹۵ | ۰.۸۰ |
| ۹۰۰ | χαμᾶζε | به زمین | ۲۹ | ۱۶۳۱۹۰ | ۰.۸۱ |
| ۹۵۰ | ἐρετμόν | پارو | ۲۷ | ۱۶۴۶۰۱ | ۰.۸۲ |
| ۱۰۰۰ | βλάπτω | ناتوان کردن | ۲۶ | ۱۶۵۹۲۲ | ۰.۸۲ |
مدل فوق حداقل یک فرض را مطرح میکند که در چاپ کاغذی مشکلآفرین خواهد بود: یعنی هنگام مواجه شدن با واژهایی در فرهنگ لغت چنین فرض میشود که گویی تمام صورتهای آن واژه قابل درک هستند؛ لذا فراگیرانی که با روشهای قدیمی، یونانی میآموزند در یادگیری افعال، به مشکلی اساسی برمیخورند چرا که معمولاً بیشترین زمان یادگیری یونانی در سال اول، صرف چگونگی روشهای مرموز ساخت افعال یونانی میشود.
با این حال، در یک محیط دیجیتال، خوانندگان میتوانند تحلیل همۀ صورتهای افعال را مشاهده کنند، مدتها پیش از آنکه بخواهند توانایی تولید آن صورتها را در خود نهادینه کنند. در این سناریو، فراگیران زودتر روی نکات اصلی دستور زبان یونانی (مانند نظام زمانها [۲۲]، وجهها [۲۳] و جهتها [۲۴]) تمرکز میکنند تا درک کنند که مثلاً یک صورت ماضی (آئوریست) تمنایی[۲۵] چه نقشی دارد. به حاشیه نویسی کامل متون منبع، لینکهایی مرتبط با دستور زبان نیز افزوده میگردد که نقش دستوری تمام واژهها را شرح میدهد.
برای مثال، نمودار درختی هومر به شما خواهد گفت واژههای یونانی «نیزه» و «شانه» هر دو در حالت برایی [۲۶] هستند و فعل ballô را توصیف میکنند، «ضربه زدن با شی پرتاب شده» (این فعل ۴۶۹ بار در هومر بهکار رفته است). اما به شما نمیگوید که برایی اول، ابزاری [۲۷] بودن را نشان میدهد (شما به کسی «با نیزه» ضربه می زنید) در حالی که دومی، برایی بیان مکان [۲۸] است (شما به «شانه» شخصی ضربه می زنید). ما باید از تگهای پیچیده تری استفاده کنیم (مانند آنچه متیو هرینگتون [۲۹]، همکار من در دانشگاه تافتس [۳۰] به کار گرفته است) یا میتوانید یک لایه حاشیه نویسی جداگانه ایجاد کنید (همانطور که من و همکارم فرنوش شمسیان [۳۱] در حال انجام آن هستیم).
بررسی مورد پیشِ رو، مبتنی بر کتاب «یونانی هومری» اثر کلاید فار است، سرآغازی برجسته و بدیع برای شروع نمودن زبان یونانی باستان که یک قرن پیش نوشته شده است. او در طراحی خود از رویکردی دادهمحور استفاده کرده است، در دورهایی که به اقتضای زمان، دادهها باید به صورت دستی گردآوری میشدند. فار دو اصل اساسی داشت: (۱) دستور زبان را به گونهایی طراحی کند تا فراگیران در اسرع وقت مستقیماً با پیکرۀ مورد علاقه درگیر شوند و (۲) از بسامد دادهها استفاده کند تا فراگیران بتوانند ابتدا با پدیدههای متداولتر درگیر شوند.
با این حال، بین اصول درگیر شدن در سریع ترین زمان ممکن با منابع متنی و تمرکز بر متداولترین واژهها اختلاف وجود دارد. از طرفی، کتاب دستور زبان سال اول فار، بندهای ۵-۱ کتاب اول ایلیاد را در درس ۱۳ معرفی میکند که اگر فراگیران هر هفته ۳ فصل از کتاب را بخوانند در آغاز هفتۀ پنجم به آن میرسند. هر چند فار از همان صفحۀ اول کتاب درسی، فراگیران را برای این کار آماده کرده است. بدین منظور از فراگیران خواسته شده است تا الفبای یونانی را با املا و تلفظ مداخل فرهنگ لغت برای هر کدام از واژههای انتخاب شده از بندهای ۵-۱ کتاب اول ایلیاد بیاموزند، که معنی هر واژه نیز کنار آن آمده است.
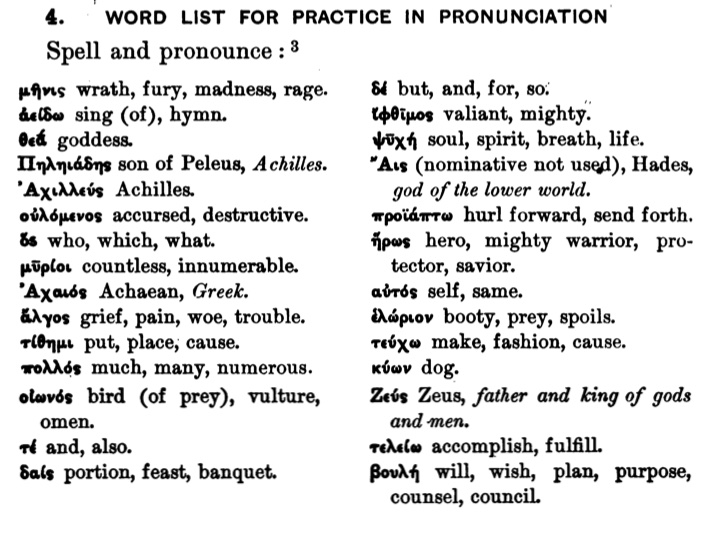
تصویر ۱ : فار، فصل ۱ ، واژگان بندهای ۵-۱ کتاب اول ایلیاد به همراه معنی.
فار واژگان ۵ سطر اول ایلیاد را در صفحۀ ۱ کتاب خود معرفی میکند. هدف اولیه این است تا فراگیران این واژهها را به منظور تمرین برای خواندن الفبای یونانی به کار گیرند. در عین حال آنها شانس این را دارند تا به طور ضمنی با واژههایی مواجه شوند که بعداً به تفصیل خواهند آموخت (به عنوان مثال واژهی tithȇmi « گذاشتن، قرار دادن، به وجود آوردن» که ریختشناسی [۳۲] پیچیدۀ آن در درس ۳۲ ارائه شده است).
پیش از پرداختن به موضوع بسامد واژهها و نیز فراگیری واژگان میخواهم در حاشیه به این نکته اشاره کنم که ما میتوانیم رویکرد متفاوتتری در پیش بگیریم، به این نحو که فراگیران آموزش خود را در روز اول با شنیدن تلفظ واژههای بندهای ۵-۱ کتاب اول ایلیاد شروع کنند. به عنوان مثال، در یک محیط دیجیتال، ما به راحتی آیکون صدا را به عنوان یک راهنما اضافه میکنیم تا فراگیران از آن به عنوان نقطۀ شروع استفاده نمایند. ما به طور قطع میتوانیم یک خوانش ساده از واژههای یونانی و معنی آنها داشته باشیم. همینطور قادریم تا همراه خوانش متن، تحلیل موزون [۳۳] آن را نیز ارائه کنیم.
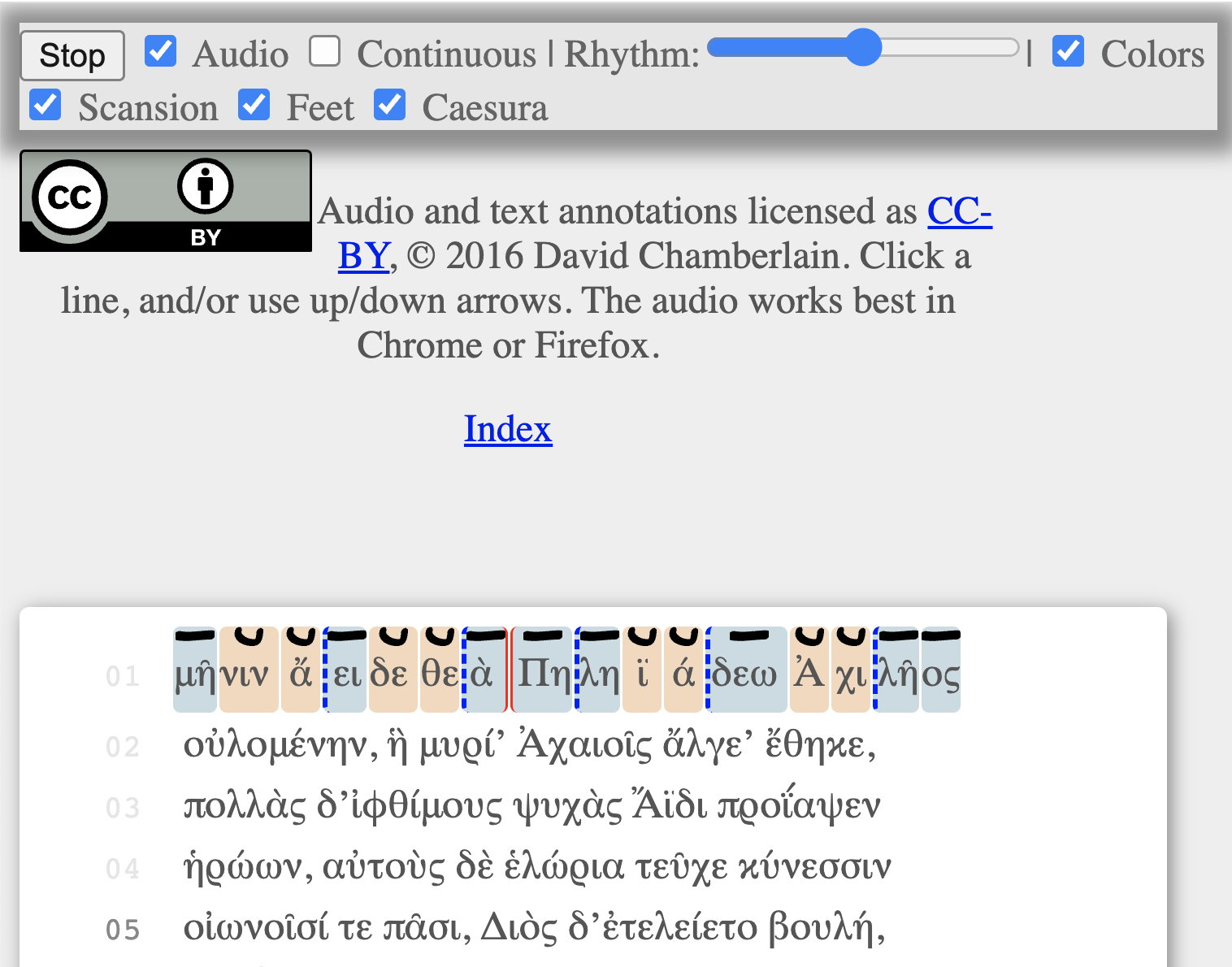
تصویر۲: تحلیل موزون اشعار و اجرای بندهای ۱۵-۱ کتاب اول ایلیاد، کاری از دیوید چمبرلین در Hypotactic .

تصویر۳: تحلیل و اجرای چمبرلین در نسخهی جدید Beyond Translation version of Perseus.
تصاویر ۲ و ۳ نشان میدهند که چطور دادههای منتشر شده با امکان دسترسی آزاد میتوانند در چندین جا در دسترس باشند. استفاده از هر کدام از این بسترها امکان به کارگیری رویکردی متفاوت را برای فراگیر مبتدی فراهم میسازد، یکی از آنها شنیدن آوای شعر شش رکنی و سه هجایی ضربْآغاز[۳۴]، از همان روز نخست است که بدین ترتیب جزو ابزار مطالعه قرار میگیرد. با اینکه چنین کاری به پیچیدگیهای شروع اضطرابآور یادگیری زبان یونانی میافزاید اما از طرفی به فراگیران این امکان را میدهد که هر چه زودتر به حماسۀ هومری به عنوان شعر نزدیک شوند. در دورانی که فراگیران قادرند با گوشیهای هوشمند از هر جایی فایلهای ضبط شده را بشنوند، دلیلی ندارد تا صوتِ شعر هومری را که میتواند بخشی ضروری از تجربۀ یادگیری به شمار آید از آنها دریغ کنیم. بسیاری از ما به صورت آنلاین به موسیقیهایی گوش میدهیم که با زبانشان آشنا نیستیم اما صبر نمیکنیم تا قبل ازگوش دادن به ترانهایی که خیال ما را به سوی خود کشانده، دستور زباناش را بیاموزیم.
به موضوع فراگیری واژگان که بازگردیم، پوشش کامل یک سری از متون معیّن مورد تاکید قرار میگیرد اما با این وجود این کار مستلزم بهایی سنگین است. هر قطعۀ واقعی [۳۵] از حماسۀ هومری و یا هر متن متعارف دیگر، واژههایی را در برمیگیرد که به ندرت ظاهر میشوند. کسانی که تمرینات کتاب فار را دنبال میکنند خود را مشغول فراگیری واژههایی مییابند که عملاً در حال به کار بردن و آموختن آنها هستند، واژههایی نظیر proiaptȏ، « به جلو پرتاب کردن، پیش فرستادن» و helôrion، «غنائم، طعمه، غارت»؛ اگرچه در باقی کتابهای ایلیاد و ادیسه، proiaptô فقط ۳ بار در جاهای دیگر ظاهر میشود و helôrion دیگر هرگز به کار نرفته است.
با این حال، اکنون میتوانیم به آسانی به فراگیر نشان دهیم که هر یک از واژههای ارائه شده در این فهرست در عمل چند بار در ایلیاد و ادیسه به کار رفته است.
| ۱ | μῆνις | ۱۶ | غضب، خشم، غیظ، عصبانیت. |
| ۲ | ἀείδω | ۴۰ | سرود خواندن، نغمه سرایی. |
| ۳ | θεά | ۱۹۹ | الهه. |
| ۴ | Πηλείδης | ۵۹ | پسر پلئوس، آخیلئوس. |
| ۵ | Ἀχιλλεύς | ۳۸۲ | آخیلئوس. |
| ۶ | οὐλόμενος | ۱۴ | نفرین شده، مُهلک، مرگبار. |
| ۷ | ὅς | ۲۰۴۳ | او، – ش(ضمیر متصل)، مذکر/ مونث؛ خود(- ش). |
| ۸ | μυρίος | ۳۲ | بیشمار، بی حدّ و حصر |
| ۹ | Ἀχαιός | ۷۲۲ | آخاییان، یونانی. |
| ۱۰ | ἄλγος | ۹۲ | اندوه، رنج، غصه، گرفتاری. |
| ۱۱ | τίθημι | ۳۷۷ | گذاشتن، قرار دادن، به وجود آوردن. |
| ۱۲ | πολύς | ۸۷۴ | زیاد، بسیار، بی شمار، |
| ۱۳ | δέ | ۱۲۱۳۸ | حروف ربط پسین: اما، و، بنابراین، برای. |
| ۱۴ | ἴφθιμος | ۴۴ | توانا، دلیر، مصمم، شجاع. |
| ۱۵ | ψυχή | ۸۱ | روح، نَفَس، حیات، روان. |
| ۱۶ | Ἅιδης | ۲ | هادس، ایزد جهان زیرزمینی. |
| ۱۷ | προιάπτω | ۴ | به جلو پرتاب کردن، پیش فرستادن. |
| ۱۸ | ἥρως | ۱۱۴ | قهرمان، محافظ، ناجی. |
| ۱۹ | αὐτός | ۱۱۲۱ | خودش، خود (مذکر، مونث، اشیاء بی جان)، همان، (یک)، او (مذکر، مونث)، آن. |
| ۲۰ | ἑλώριον | ۱ | غنائم، طعمه، غارت. |
ما به سادگی میتوانیم در کل حماسۀ هومری بسامد آن دسته از واژههای فرهنگ لغت را که زیر سطح آستانه قرار میگیرند شناسایی کنیم. بنابراین فراگیران میتوانند یادگیری خود را اولویت بندی کنند، بدین ترتیب که واژههای بالاتر ازسطح آستانه را به صورت یادگیری فعال در عمل بهکار برده و بیاموزند و واژههای نامعمول (مانند helôrion) را که پایینتر از سطح آستانه قرار میگیرند به صورت یادگیری غیر فعال فرا بگیرند.
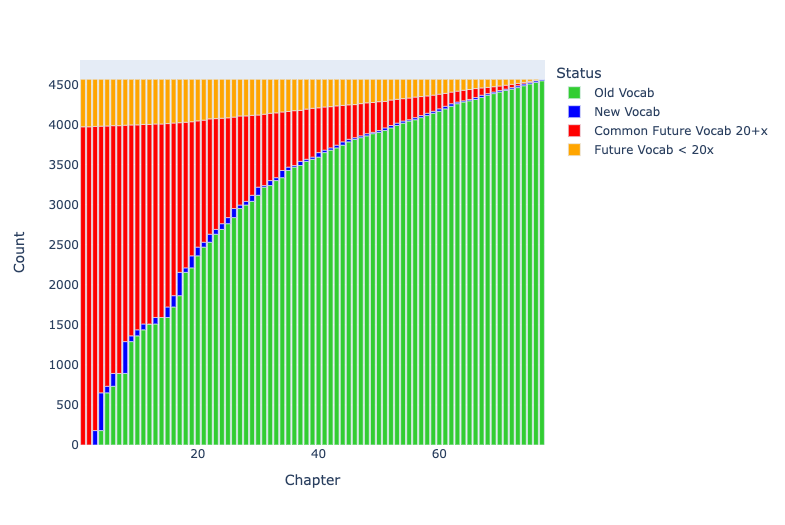
نمودار ۲ : فراگیری واژگان در کتاب اول ایلیاد مطابق فار با بسامد نقطه برش x+۲۰ در حماسۀ هومری
نمودار ۲ واژهها را به چهار دسته تقسیم میکند. محور y کلِ واژههای موجود در کتاب اول ایلیاد را نشان میدهد در حالیکه محور x بیانگر ۷۷ فصلِ کتاب فار است. نوار نارنجیِ قسمت بالا نشانگر واژههایی است که پیشتر مشاهده نشدهاند و در پایین سطح آستانۀ هدف قرار گرفتهاند (در اینجا برابر۲۰ واژه، بنابراین واژههای مشخص شده با رنگ نارنجی ۱۹ بار یا کمتر در حماسهی هومری بهکار رفتهاند). نوار قرمز رنگ حد فاصل بین واژههای پیشتر دیده نشده و واژههای متداول را (که ۲۰ بار یا بیشتر در حماسۀ هومری به کار رفتهاند) مشخص میکند. نوار آبی نشان میدهد که فراگیران پس از تسلط بر واژگان هر فصل معیّن، چند واژۀ جدید از کل کتاب اول ایلیاد را میفهمند. نوارهای سبز این امکان را به فراگیران میدهد تا شمار واژههایی را که لازم است تشخیص دهند، دریابند. مطابق طرح فار با اتمام فصل پایانی، آنها به یک پوشش صد در صدی از کل واژگان کتاب اول ایلیاد دست پیدا میکنند.
۱۱۱۸ واژه از مجموع ۴۵۶۳ واژگان بهکار رفته در کتاب اول ایلیاد، مداخل مجزایی در فرهنگ لغت دارند. با این وجود اگر بخواهیم بر روی آن دسته از واژههای فرهنگ لغت که ۲۰ بار یا بیشتردر حماسۀ هومری به کار رفتهاند تمرکز کنیم، شمار ذکر شده به ۶۵۵ مدخل که در عمل با تسلط به کار گرفته میشوند کاهش مییابد. ۴۶۳ واژۀ دیگر تنها ۵۹۳ واژه از مجموع واژگان را به خود اختصاص داده است (در نمودار فوق به رنگ نارنجی نمایان است)، یعنی بخش عمدهایی از آنها تنها یک بار در کتاب اول ایلیاد به کار رفتهاند. فراگیران میتوانند به جای تسلط فعال بر آنها بر شناساییِ فرم صوری این واژههای معمول درسی در بافت متن توجه نمایند.
اگر بخواهیم نقطه برش را برای آن دسته از واژههای فرهنگ لغت که ۳۰ بار یا بیشتر در حماسۀ هومری ظاهر میشوند افزایش دهیم، تعداد کلمات برای یادآوری فعال را از ۶۵۵ به ۵۶۵ واژه کاهش میدهیم. ۹۰ مدخل فرهنگ لغت از کتاب اول ایلیاد، بین ۲۱ تا ۳۰ بار در حماسۀ هومری به کار رفتهاند. از مجموع ۴۵۶۳ واژۀ موجود در کتاب اول ایلیاد،۷۳۰ واژه در دستهایی قرار میگیرند که کمتر متداولاند و به صورت غیرفعال در بافت متن شناسایی میشوند.
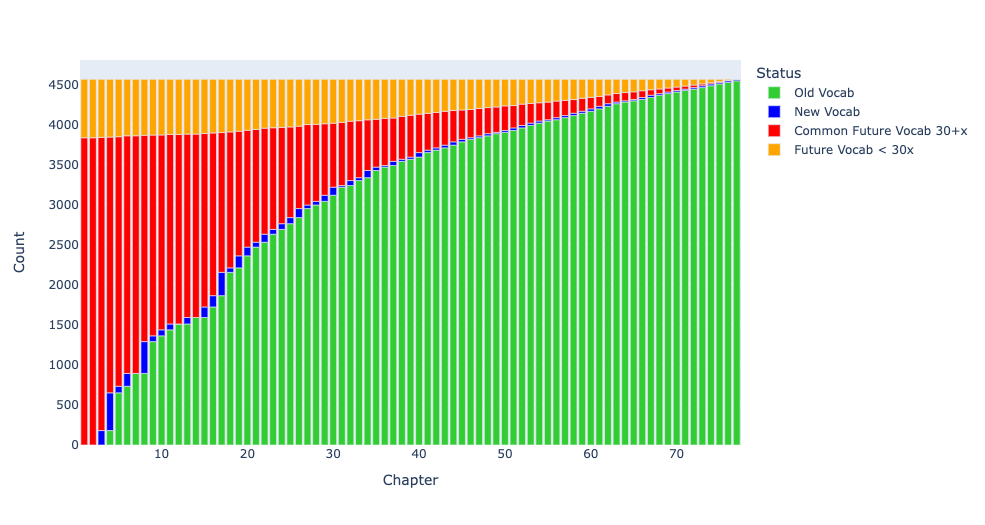
نمودار ۳ : فراگیری واژگان در کتاب اول ایلیاد مطابق فار با بسامد نقطه برش x+۳۰ در حماسۀ هومری
با افزایش نقطه برش از ۲۰ به ۳۰ واژه، بر شمار واژههایی که سعی نمیکنیم به صورت یادگیری فعال مسلط شویم میافزاییم، اما نمودار ۳ نشان میدهد که این تغییر اساسی نیست؛ بیشتر خوانندگان نیاز به دقت بیشتری دارند تا متوجه تفاوت آن با نمودار ۵ شوند.
ایراد تمرکز بر کتاب اول ایلیاد (یا هر کدام از کتابهای ایلیاد یا ادیسه) این است که بسیاری از واژههایی را که در کل حماسۀ هومری متداول هستند اما در کتاب انتخابی ما دیده نمیشوند، از دست خواهیم داد.
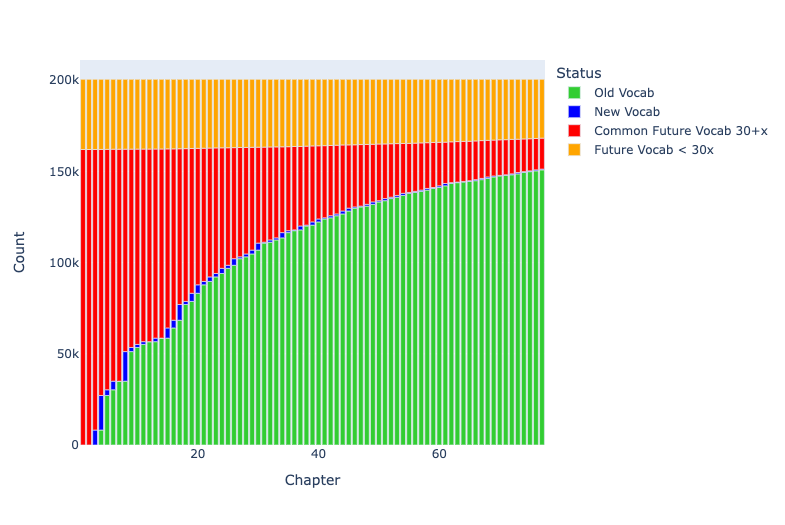
نمودار ۴ : یادگیری واژگان کتاب اول ایلیاد در مقایسه با واژگان حماسه های هومری به عنوان یک کل
در حالی که ناحیۀ سبز در نمودارهای ۲ و ۳ در نهایت، تمام واژگان کتاب اول ایلیاد را پوشش میدهد، توانایی تشخیص هر مورد واژگانی در کتاب اول ایلیاد زبانآموزان را آماده میکند تا فقط ۱۴۵۰۲۶ واژه از کل ۲۰۰۵۱۸ (۷۲%) واژگان موجود در حماسههای هومری را بهعنوان یک کل تشخیص دهند.
اگر به نقطه برش ۲۰ واژه در هومر بازگردیم، ۶۵۵ بُنواژه [۳۶] در این دسته قرار میگیرند. افزودن این ۹۰ مدخل اضافی به منظور تسلط فعال، درک شمار کل واژههای حماسۀ هومری را از ۱۴۵.۰۲۶ به ۱۵۰.۸۴۸ واژه (از %۷۲ به %۷۵) افزایش میدهد.
مشکل این است که بسیاری از واژههای فرهنگ لغت که در هومر متداول میباشند در کتاب اول ایلیاد دیده نمیشوند. فهرست زیر، ۲۰ واژۀ متداول از واژگان هومری را نشان میدهد که در کتاب اول ایلیاد وجود ندارند (تعجبی ندارد که تلماخوس در صدر این فهرست قرار دارد).
| جمع کل | بسامد | بُنواژه | واژهنامه کوتاه (به سبک مداخل شیکاگو) | |
| ۱ | ۲۴۴ | ۲۴۴ | Τηλέμαχος | تلماخوس |
| ۲ | ۴۸۴ | ۲۴۰ | ἔγχος | نیزه |
| ۳ | ۷۱۶ | ۲۳۲ | μνηστήρ | خواستگار |
| ۴ | ۹۲۹ | ۲۱۳ | ξένος | مهمان |
| ۵ | ۱۱۲۱ | ۱۹۲ | τεῦχος | سلاح |
| ۶ | ۱۳۱۱ | ۱۹۰ | κελεύω | مجبور کردن، دستور دادن |
| ۷ | ۱۴۸۷ | ۱۷۶ | ἀλλήλων | یکدیگر |
| ۸ | ۱۶۵۰ | ۱۶۳ | Ἄρης | آرس |
| ۹ | ۱۷۹۶ | ۱۴۶ | δόμος | خانه؛ ردیف سنگ |
| ۱۰ | ۱۹۳۲ | ۱۳۶ | ταχύς | سریع |
| ۱۱ | ۲۰۶۷ | ۱۳۵ | ὀτρύνω | برانگیختن |
| ۱۲ | ۲۱۹۸ | ۱۳۱ | ἄστυ | شهر |
| ۱۳ | ۲۳۲۸ | ۱۳۰ | πατρίς | سرزمین پدری |
| ۱۴ | ۲۴۵۷ | ۱۲۹ | δύω | در آب فرو بردن |
| ۱۵ | ۲۵۸۳ | ۱۲۶ | ἐκεῖνος | شخصی که آنجا است |
| ۱۶ | ۲۷۰۹ | ۱۲۶ | τῷ | بنابراین |
| ۱۷ | ۲۸۲۷ | ۱۱۸ | πάσχω | تجربه کردن |
| ۱۸ | ۲۹۴۳ | ۱۱۶ | δῆμος | مردم، (در اصل روستایی) |
| ۱۹ | ۳۰۵۹ | ۱۱۶ | ἀμφότερος | هر یک از دو |
| ۲۰ | ۳۱۷۳ | ۱۱۴ | πεδίον | دشت |
جای تعجب نیست که ما واژههای خواستگاران (mnêstêres) یا مهمانان (xenos) را نمییابیم چرا که اینها نیز همانند نام تلماخوس، بیشتر مختص اودیسه هستند. اما کتاب اول ایلیاد واژههای متداولی را که برای نیزه ها (Enchos) یا سلاح ها (teuchos) اغلب در کل ایلیاد ظاهر می شوند، ندارد.
میتوان رویکرد متفاوتی را اتخاذ کرد و به منظور یادگیری هر یک از واژههای متداول فرهنگ لغت حماسۀ هومری، تقریباً از بالای فهرست شروع کرده و به سمت پایین حرکت کرد. (شما احتمالاً نه تنها با متداولترین واژهها، بلکه با متداولترین اسمها و افعال با قاعده شروع میکنید.) بدین منظور باید به نمونههایی از یونانی هومری که خارج از کتاب اول ایلیاد وجود دارند نگاه کنید تا ببینید کلماتی مانند mnêstêres و xenos چگونه به کار رفتهاند. انجام چنین کاری ما را از تمرکز بر روی کتاب اول ایلیاد دور میکند و یا نیاز به کار اضافی دارد؛ اما میتواند منجر به نتیجۀ متعادلتری شود.
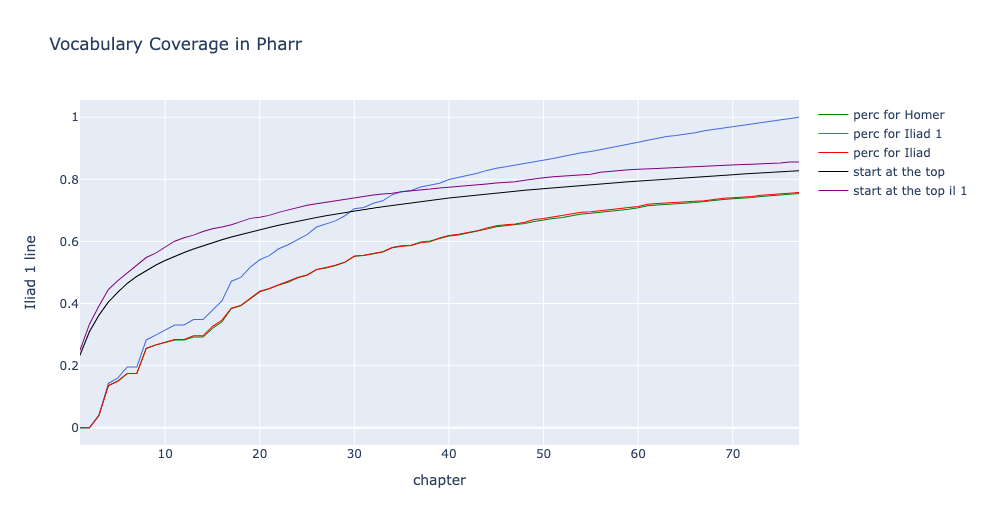
نمودار۵: دو رویکرد برای فراگیری واژگان هومری
نمودار ۵ دو رویکرد را به منظور یادگیری واژگان هومری به تصویر میکشد. خطوط بالا و پایین یادگیری واژگان را برای فراگیرانی که بر روی ۷۷ درس از کتاب فار کار میکنند نشان میدهد. اگر فراگیران به کل واژگان موجود در کتاب اول ایلیاد (بدون کنار گذاشتن واژههای کم بسامد) تسلط یابند، در اینصورت %۷۶ از کل واژههای به کار رفته در حماسۀ هومری را دیدهاند. بالاترین خط، نشانگر پوشش صد در صدی واژگان کتاب اول ایلیاد است.
دو خط وسط نتایجِ حاصل از رویکرد از بالا به پایین [۳۷] را منعکس میکنند، جایی که ما واژهها را صرفاً بر اساس بسامد میآموزیم (از این رو این خطوط انحناهای بسیار ملایمی دارند). به جای یادگیری ۱۱۱۸ مدخل مستقل فرهنگ لغت که کتاب دستور فار پوشش داده است، ما ۱۰۰۰ مدخل متداول هومر را یاد میگیریم. این دو خط بسیار نزدیک ترند. با اینکه فراگیران فقط بر ۸۵.۵% از کلمات در کتاب اول ایلیاد تسلط مییابند، اما %۸۳ از کل واژگان را در حماسۀ هومری دیدهاند. ممکن است رعایت دقیقتر کل بسامدهای واژگان هومری و تمرکز کمتر بر واژگان یک متن خاص برای فراگیران رضایتبخشتر و مؤثرتر باشد. آنها یاد میگیرند %۱۵از واژگانی را که در فهرستشان نبود، شناسایی کنند.
به طور کلی، نکته این است که اینک فراگیران قادرند پیشرفت خود و معنای واژگان جدیدی را که بعداً مواجه میشوند در زمان واقعی پیگیری کنند. فرضیه ما این است که این کار باعث افزایش انگیزه و رضایت آنها میشود و فراگیران را به طور کاملتر و برای مدت زمان طولانیتری درگیر میکند. گام بعدی طراحی شیوههایی به منظور راستیآزمایی این فرضیه خواهد بود. با این حال، در بخش دوم این مقاله ابتدا باید روش دیگری را برای ردیابی دقیقتر واژگان از پیش مشاهده شده و مشاهده نشده ارائه کنیم.
[۱] Clyde Pharr’s Homeric Greek (D.C. Heath & Co., ۱۹۲۵)
[۲] modern languages:
در مبحث تدریس زبان خارجی به زبانهایی اطلاق میگردد که امروزه جزو زبانهای زنده به حساب میآیند مثل زبان ایتالیایی یا فرانسوی، در مقایسه با زبانهای باستانی از قبیل لاتین یا یونانیباستان.
[۳] threshold
حداقل سطح مهارت که فراگیران یک زبان خارجی برای کسب توانایی کارکردی در زبانی که در حال یادگیری آن هستند باید به آن برسند.
[۴] Attic Tragedy
[۵] Herodotus
[۶] the Ionic dialect
[۷] Thucydides
[۸] Attic
[۹] comedies of Aristophanes
[۱۰] the dialogues of Plato
[۱۱] active command
[۱۲] passive recognition
[۱۳] John Wright
[۱۴] Paula Debnar
[۱۵] Kurosawa
[۱۶] Grateful Dead
[۱۷] Allen’s 1920 Oxford Classical Text
[۱۸] normalize
[۱۹] grave accent
[۲۰] normalization
[۲۱] Ethan Yates
[۲۲] system of tenses
[۲۳] moods
[۲۴] voices
[۲۵] aorist optative
[۲۶] dative
[۲۷] instrumental
[۲۸] location
[۲۹] Matthew Harrington
[۳۰] Tufts
[۳۱] Farnoosh Shamsian
[۳۲] morphology
[۳۳] metrical analysis
[۳۴] the dactylic hexameter
[۳۵] substantial passage
[۳۶] lemma
[۳۷] the top-down approach