This paper makes a simple, but significant, observation. Vocabulary keeps growing in any corpus — there is no final, fixed set of words. That phenomenon appears with any natural language corpus. Here I emphasize the significance for students of Homeric epic. The Homeric Iliad and Odyssey contain about 200,000 running words and we can see how the number of dictionary entries (e.g, anêr, ‘man’) and of inflected forms derived from dictionary entries (e.g, andros, ‘of a man,’ andri) increase slowly but continuously: 8,792 dictionaries appearing as 31,664 different account for the 200,581 running words that appears in the Perseus Dependency Treebanks of the two epics.
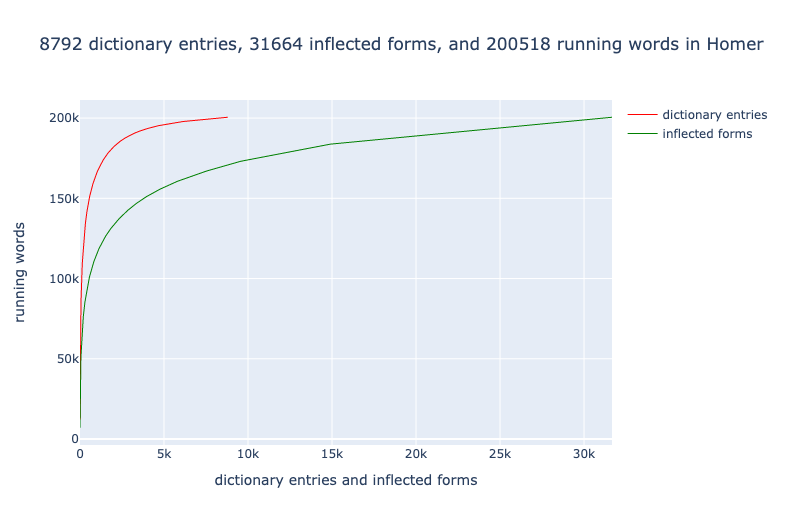
First, readers should pause and take note of the fact that two curves in Figure 1, smooth though they are, were not produced by a mathematical formula. These are individual data points. A program sorted the dictionary entries and inflected forms in the Homeric Epic by frequency, starting with the most frequent, then working its way down the list, adding the frequency of each new term to the running total. There is an underlying pattern to vocabulary frequencies such that we generate curves that exhibit no outliers at this resolution. This is not a scatterplot that we have fitted to a curve. This figure shows two series of linguistic data that follow an extraordinarily regular pattern.
Heaps’ Law is an empirical law that provides a mathematical model for the growth of vocabulary in a corpus and for the growth of dictionary entries and of forms through the epics. The mathematical model offered by Heaps’ Law is based on the observation that vocabulary growth follows a power law, i.e., a few very common entries account for a disproportionate percentage of total words in a corpus. As we move through the corpus, the number of new dictionary entries and inflected forms slows but it does keep growing. If we had 500,000 running words, we would have more dictionary entries and inflected forms, if we had 1,000,000 running words, more still, and so on. Many words that appear only once in the first 200,000 words would reappear.
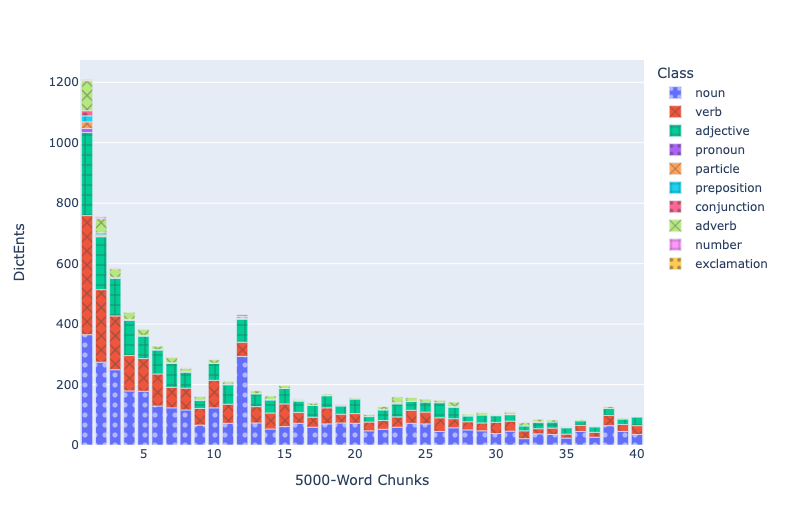
Figure 2 illustrates the number of new dictionary entries encountered in each 5,000 word chunk of the Iliad and the Odyssey. The sequence above departs from the traditional ordering of books. It scans the books of the Iliad and Odyssey in this order: Books 1, 10-19, 2, 20-24. Chunk 12 above contains an unexpected spike. Students of Homer may well guess that chunk 12 contains the catalogue of ships (hence, the unexpectedly large new vocabulary reflects a surge in the number of new nouns).
Chunk 10, which exhibits a smaller, but sudden, spike covers Iliad 18.28-19.107 and, thus, the description of Hephaestus’ workshop and Achilles’ shield, both of which would plausibly introduce new vocabulary, including more verbs as well as nouns.
By contrast, chunk 9 drops precipitously after the first 8 chunks had declined according to a fairly clear pattern. This contains Iliad 16.259-17.95, most of the aristeia and death of Patroclus. At this point, the narrative may be reprising and pointing backwards towards language and formulae that it had cultivated in the preceding books’ battles.
If we reverse the order and start with the Odyssey, the basic picture remains the same.
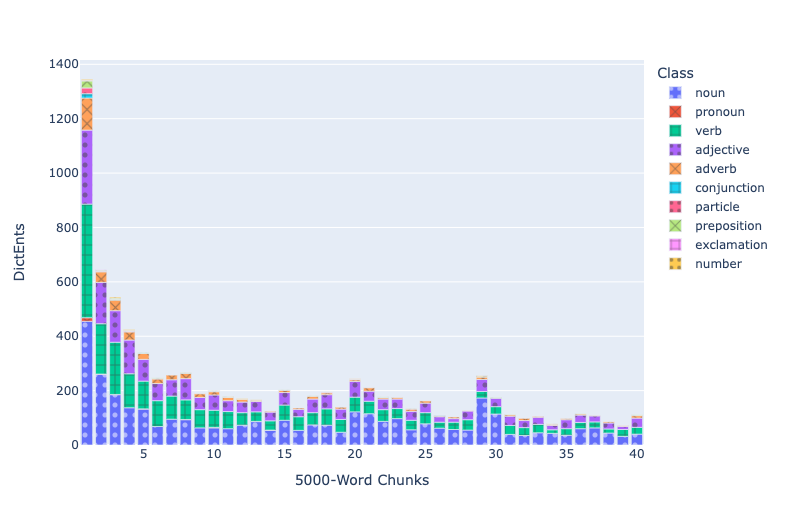
In figure 2, the bulge caused by the catalogue of ships in Iliad 2 is less pronounced, both because it is counted later (when some of the place names have been encountered) and because it is split between two of the 5,000 word chunks (29 and 30). The point of both figures 2 and 3 is to show that we continue to encounter new vocabulary in the last 5,000 word chunk, even after analyzing the previous 195,000 running words.
What are the new words that we encounter after reading through 195,000 words of Homeric poetry? If we start with the Iliad and follow the order of books as described above, the final chunk begins with Odyssey 8.399 and the first 20 (of 41) unseen words are:
| Greek word | short definition | |
| 1 | πρόειμι | go forward |
| 2 | νεόπριστος | fresh-sawn |
| 3 | ὕμνος | a hymn |
| 4 | ἐπαρτύω | to fit on; fix; prepare |
| 5 | αὐτόδιον | straightway |
| 6 | οἰνοποτήρ | a wine-drinker |
| 7 | βιώσκομαι | to quicken |
| 8 | ἀποπροτέμνω | to cut off from |
| 9 | ἔμμορος | partaking in |
| 10 | μεταβαίνω | to pass over from one place to another |
| 11 | δουράτεος | of planks |
| 12 | ἀκρόπολις | the upper city |
| 13 | ἐκπρολείπω | to forsake |
| 14 | ἀμφιπίπτω | to fall around |
| 15 | εἴρερος | bondage |
| 16 | εἰσανάγω | to lead up into |
| 17 | ἐπιψαύω | to touch on the surface |
| 18 | ἀνώνυμος | without name |
| 19 | κυβερνητήρ | pilot |
| 20 | Νήριτον | Neritus (a personal name) |
Of these 20 words, only one is a proper name, i.e., new vocabulary does not mainly consist of unfamiliar people or places.
If we scan the Odyssey first, then the first 20 unseen words in our final chunk are:
| Greek word | short definition | |
| 1 | μέσφα | until |
| 2 | πολιοκρόταφος | with gray hair on the temples |
| 3 | θεόδμητος | god-built |
| 4 | ὑγιής | sound |
| 5 | κηρεσσιφόρητος | urged on by the Κῆρες |
| 6 | φυλάζω | to divide into tribes |
| 7 | νήνεμος | without wind |
| 8 | Θρῄκηθεν | nodef |
| 9 | κορθύνω | to lift up |
| 10 | φῦκος | rouge |
| 11 | κλήδην | by name |
| 12 | Μυκήνηθεν | from Mycene |
| 13 | ἀφρήτωρ | without brotherhood |
| 14 | ἀνέστιος | without hearth and home |
| 15 | ὑποδεξίη | the reception of a guest |
| 16 | σέυω | to rush |
| 17 | Δηίοπιτης | Deiopites (a personal name) |
| 18 | ἀπομυθέομαι | to dissuade |
| 19 | ἀλήϊος | without share of booty |
| 20 | ἀκτήμων | without property |
This chunk begins at Iliad 8.508. It also contains only one unseen proper name.
We cannot talk about what words and expressions were active in the oral tradition. We cannot say that lines with no parallels are not formulaic, i.e., that they were not learned and repeated in multiple contexts. We can only say that we have no parallels. We can, if we can combine a good understanding of probability with a solid grounding in how poetry works, begin to build more sophisticated models about what might appear if we had more epic on more subjects or more epic poetry on subjects that are not common in the current corpus (e.g., night raids such as Iliad 10). But then we are making our assumptions and our models explicit.
Acknowledgements
This work was made possible by the Beyond Translation Project , funded by NEH HAA-266462-19 and by support from the Data Intensive Studies Center at Tufts University.